7 Privacy related questions about contact tracing apps
9 June, 2020
By Julián Salas & Cristina Pérez.
Now that in many countries the lockdown measures and restrictions on the mobility implemented to control the COVID-19 pandemic are being relaxed gradually, contact tracing is taking place as a measure for epidemic control, followed by quarantine and isolation of suspected cases.
Contact tracing may be carried out by volunteers surveying people with symptoms and asking them to remember their recent contacts or may be carried out automatically through an app in our mobile phones.
Besides the technological limitations, there are also privacy concerns, legal requirements (compliance with the GDPR) and technical/sociological characteristics that must be considered for automated contact tracing.
There are different conceptions of privacy such as the data protection impact assessment (DPIA) released by the NHSX, the unit from United Kingdom Government responsible for developing best practice of National Health Service (NHS) technology, which claimed that their contact tracing/proximity tracing app preserved anonymity. While, an analysis of the NHSX Contact Tracing App, concluded that the data in the NHSX app is ‘capable’ of revealing an individual’s identity, and remarked that “whether NHSX intend to do this is not a relevant question from a legal standpoint, the question is whether it reasonably could.”
There are diverse systems, such as the system of tokens that store a register of proximity with other tokens which are randomly distributed by allowing for individuals to pick from boxes filled with them. A contact list is generated locally on each token when it detects a near token. And the system broadcasts a list of the infected users on a regular basis to every token. In this way, every token can locally compare this list to the contact list it has stored.
We present some brief explanations and thought-provoking questions on this topic, as we think that it is important to have a public debate on which system to deploy, to measure the privacy risks that the system may bring to the population, and to be transparent with such information.
1. Are there any concerns about privacy and accuracy?
A recent survey in the US concluded that 88% of the citizens will be willing to install COVID-19 contact tracing apps if the app is perfectly accurate and private. But only 26-29% if the app could leak data to the US government, their employer, a technology company or a non-profit organization.
Any classification algorithm will necessarily generate both false negatives and false positives, for example, either not all people at 2m distance are detected by Bluetooth or people at larger distances will also be detected.
Regarding privacy, there are different arguments, that go from: “Hilarious seeing people whine about the government tracking them when Google has been doing it for years…” to “Considering the absence of evidence of their efficacy, are the promises worth the predictable societal and legal risks?”
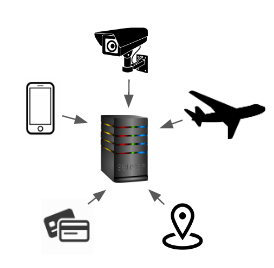 Figure 1: Collect everything
Figure 1: Collect everything
2. Location or proximity tracking?
On a second survey, some respondents preferred proximity tracking as they argued that “proximity tracking seems better from a privacy perspective. Perhaps even more accurate?” while others said it is more invasive than location tracking: “The government doesn’t have to know with who I am.” or “It feels more of an invasion of privacy, due to the subtleness of it.”
Proximity tracking may be estimated from location tracking if two phones are on the same cell (from telephone operators) during the same amount of time they have met with high probability. Location tracking could be used for estimating the locations with potentially infected persons. This could be used to prevent infections from a surface to a person.
3. How many people should use it to be effective?
The probability that a contact is detected equals the number of pairs from the total that have the app installed. If the proportion of persons who have installed the app is x if in the population of n persons, the proportion of the contacts detected would be x2 of the total. So, if x=0.2 or 20% of the total population install the app, then it will detect 0.04 or around 4% of the total possible contacts.
4. Why change pseudonyms?
Most contact tracing apps use ephemeral identifiers, that are changed over time. Each identifier is used during a small amount of time, typically between a few minutes and a few hours.
To understand why it is useful to change identifiers, imagine an attacker that installs Bluetooth receivers over a city, and collects all Bluetooth identifiers of smartphones that get close to the receivers. Now imagine a user, Bob, that generates a pseudonym, and keeps using the same pseudonym over time, without never changing it. Each time Bob gets close to an attacker’s receiver, the attacker will know that the user is in that location. Over time, the attacker will get a picture of the whereabouts of the user, tracking all the locations where Bob has been close to a receiver. Moreover, even though the attacker does not know that Bob is behind the pseudonym, the information about his locations can be used to reidentify him.
Now imagine another user, Alice, that has been changing her pseudonyms every 10 minutes. Each time Alice gets close to an attacker’s receiver, the attacker will collect her pseudonym, but since it will be different each time, the attacker will not be able to get a picture of her movements around the city, nor reidentify her given the locations.
For the attack to be prevented, given two different identifiers, the attacker should not be able to infer whether they belong to the same user. In centralized systems, where pseudonyms are created by a server, only the server (and the user itself) are able to know whether two identifiers belong to the same user. Therefore, these systems provide location traceability protection over eavesdroppers and external attackers. Decentralized systems, where users create the identifiers themselves, can go one step further, and provide protection even from the server.
5. Centralized or decentralized architectures?
Privacy-preserving contact tracing apps are being designed following two different approaches. On the one hand, there are centralized systems where a central server, managed by an authority (e.g. the government), plays a central role in the protocol and executes some critical operations. On the other hand, there are decentralized systems, where computations are made locally in the users’ smartphones, and that minimize the role of the central server.
In the context of proximity tracing applications, two main tasks can be decentralized: the generation of the ephemeral identifiers (exchanged by phones each time they are in range); and the computations of the estimations of the level of exposure to the virus (from the beacons exchanged by the phones and the positive COVID-19 tests).
With respect to privacy, there are obvious differences in both approaches, especially if the entity running the server can be considered an attacker. In centralized systems, the server is able to link all the pseudonyms of a user (regardless of whether he has tested positive for COVID-19). Moreover, whenever a COVID-19 positive user uploads the ephemeral identifiers that he has collected, the server is able to link them to the permanent identifiers of the users, thus gaining knowledge about the interactions of the users of the system.
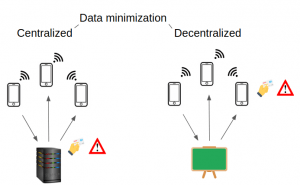
Figure 2: data minimization architectures
6. How the app knows if you were in contact with a positive case?
Each time two smartphones (that run a contact tracing app in the background) get close together, they exchange their ephemeral identifiers. Each smartphone maintains a list of all the ephemeral identifiers that it has seen during the last days.
Then, whenever a person is tested positive for COVID-19, she can decide to upload the ephemeral identifiers that her smartphone has used during the period of time she was infectious, or the list of contacts she has seen during that period. The exact information that is uploaded to the server depends on the architecture of the platform being used. In centralized systems, the COVID-19 positive user may upload the ephemeral identifiers of the contacts she has seen, and then the server processes this information to alert these contacts if they are at risk. In decentralized systems, the COVID-19 positive user may upload her ephemeral identifiers (corresponding to his infectious period). Then, other users download this information, and compute, locally on their phones, whether they are at risk.
7. For how long should data be stored?
According to GDPR data should be stored for the minimal amount of time for the task for what it was collected. Considering that the incubation period for COVID-19 is 15 days, many apps store data for 15 days in others for 30 days. There are some others (as in Poland) that plan to keep the data for 6 years. Or some may keep it forever if its purpose is for research.
In PACT comment that their app gracefully “sunsets” once the pandemic has passed, since no more uploads occur, while remaining active and available to prevent future epidemics from becoming full-blown pandemics. We wonder if this can be considered a sunset clause if the app is still active and collecting data?
Conclusions
The design of privacy preserving contact tracing apps is far from trivial: many design decisions for which there are no clear good choices have to be taken. These decisions affect the privacy properties of the systems but also have consequences on many other levels (such as security, functionality, or even legal and political aspects). In this article, we have reviewed some of the discussions that have arisen in the community when designing contact tracing applications.
We hope that the questions that we have raised give the readers some idea of the privacy enhancing mechanisms behind the contact tracing technologies and the motivation to look out for more information about this topic.
Article by Julián Salas and Cristina Pérez, researchers of the K-riptography and Information Security for Open Networks (KISON) group at the UOC’s Internet Interdisciplinary Institute (IN3) and the Center for Cybersecurity Research of Catalonia (CYBERCAT).