
Open data: Are we there yet?
10 July, 2019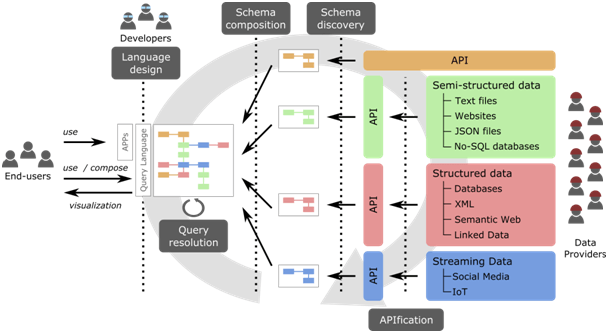 uoc-in3-open-data-all-3
uoc-in3-open-data-all-3We are flooded with open data and bombarded with constant news of new open data initiatives by all kinds of local, regional and national organizations. As an example, see the open data portal of the city of Barcelona, the Catalan catalogue or the Spanish one. To give you an idea, the Spanish portal registers more than 20.000 open data resources while the European data portal, which aggregates all open data initiatives in Europe, links to over 400.000.
Still, what is the real impact at the citizen level of all these initiatives? In my personal opinion, rather limited. Technically speaking, all these initiatives can all be called “open data” as they do offer data that it’s freely accessible to anyone interested. But, as I like to say, my mother cannot actually use any of them. Data may be open but data has not been really opened to the citizens. My mother does not natively read JSON or CSV, cannot call APIs or open XML files, just to mention some of the data formats used to publish the data. She will be able to open the XLS ones but I doubt she’ll be able to comprehend the data that will pop up by just looking at the names of the columns. Even less, to join the data from one source with the data in another source to get the response she is looking for.
Don’t get me wrong. Open data has been a major step forward for the public administrations and its economic impact is undeniable. Report on the Economic Benefits of Open Data presents compelling evidence of such impact across a number of dimensions (jobs, costs savings, efficiency gains,…).By the way, you can still participate in the survey to collect inputs for the next report!

Nevertheless, I believe this represents just the tip of the iceberg. I believe we are far from exploiting the full potential of the open data movement. Right now, all interesting applications of open data are thanks to third-party teams that take some specific open data sets and build interesting individual applications from them. A great example of this kind of contributed applications is the large number of hackathons organized under different themes devoted to processing and digest open data sources in order to make something more useful (from the point of view a non-techie citizen) out of them. Feel free to take a look at the winners of the 3rd edition of the EU Datathon. It shouldn’t come as a surprise that they are all about making the data more accessible via, for instance, nice graphical visualizations and analytics.
If we are not there yet, then what do we need to reach the full potential of open data?
Or, following with my mother (sorry, mum!), what needs to be done to make sure any citizen can rely on the public open data sources to easily get reliable answers that help them in their daily life?. As we like to say in software engineering, there is no silver bullet: no single development or tool, by itself, promises even one order of magnitude improvement within a decade in productivity, in reliability, in simplicity. But we propose the following combination of characteristics for new open data solutions as the closest we can get to a silver bullet for open data:
- Unify the publication format of open data to simplify the generic manipulation of any resource. Even more, we propose to use REST-based APIs as the default format to publish and give access to resources. The owners of the resources can easily “apify” any data they have. Moreover, following standard REST practices would allow open data consumers to reuse the plethora of tools already existing for managing REST APIs. This standard is the most common in all other kinds of data resources published by private companies (e.g. ProgrammableWeb lists more than 20000 APIs for all kinds of domains, from nutrition to weather to transportation…), which would simplify combining public and private open data.
- Clear definition of the type and schema of the data behind each resource. Administrations need to do a better job in describing what kind of data is available behind each resource. And in a precise and machine-readable way that can be then used to automatically analyze the data. This schema can be automatically discovered but the precision is obviously much higher when the data owner is the one specifying the classes, properties and relationships of the data in the resource.
- Be honest with the quality of the data you’re providing. Publishing the data is not enough. You need also to explain the quality of such data. How “fresh” is it? How often is updated? How sure you’re about the data itself? How reliable and performing is the infrastructure hosting the data?. All these aspects are important when deciding what data source to use in a given app (it’s often the case that you can find more than one provider for the same data).
- Link your open data. Any meaningful open data application typically requires the combination of 2 or more data sources. Potentially from different portals (e.g. mixing Barcelona data with a Catalan resource). As for the discovery part, potential compositions can be automatically detected but data owners should provide explicit links between their datasets to simplify building apps that select, combine and merge data, even across different organizations.
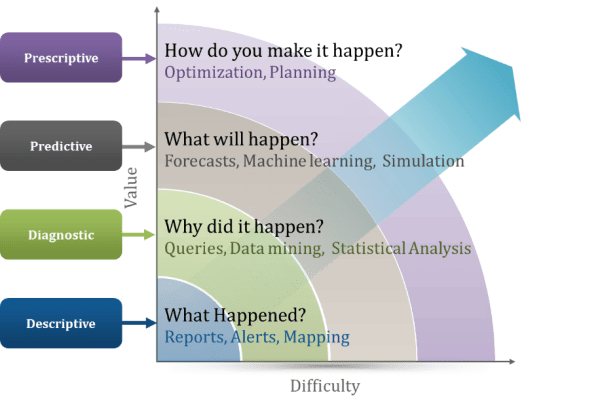
- Provide conversational interfaces to access the data. Previous requirements mainly concern the organization of the data in the back-end but, once organized, we still need to simplify the way a citizen can browse it. Chatbots could be a good solution. The user would be able to ask questions in natural language (English, Spanish, Catalan,…) and the bot would then try to find the right answer exploring the data on behalf of the citizen. Advanced language processors are even able to understand complex questions involving the aggregation and analysis of the data (e.g. give the average price or the top 5 products). The graphic below describes the different levels of complexity (and therefore usefulness) in the questions we may want to ask on a dataset.
At SOM (Systems, Software and Models Lab), we are working on several of these issues as part of our “Open Data for All” project. Our goal is to empower all citizens to exploit and benefit from the open data, helping them to become not only consumers but also creators of data that add new value to our society. In this sense, the project will automatically infer a unified global schema of the knowledge available in open data sets and present that schema to the average citizen in a way she can easily browse and query to get the information she needs. This request will be then transparently translated into a combined sequence of accesses to the required data sources to retrieve, visualize and republish it (if desired). When several data sources could be used (e.g. due to an overlap in the exposed data) quality aspects of the source or even monetary costs (some sources may be only partially free) will be taken into account to provide an optimal solution.
This figure tries to summarize our vision. You can track our progress on the GitHub organization of the project: https://github.com/opendata-for-all
And, before you ask, no, my mother is unable to use our tools. We are not yet there either but hopefully moving quickly closer to the final goal of opening the open data and having open data for all.
Jordi Cabot
Research Professor
jordi.cabot@icrea.cat
Systems, Software and Models (SOM) Research Lab



