
Ciencia de datos de para el bienestar planetario
26/06/2019
El pasado 15 de mayo tuvo lugar el UOC Data Day, un evento gratuito organizado por los Estudios de Informática, Multimedia y Telecomunicación de la UOC con el objetivo de hablar sobre ciencia de datos y todo lo que le rodea.
La primera ponente, después de la presentación del evento por la Dra. Teresa Sancho, directora de programa del Grado en Ciencia de datos de la Universidad Oberta de Catalunya, fue Ana Freire. Ana es ingeniera en informática y doctora también en ingeniería informática por la Universidad da Coruña. Actualmente, es profesora investigadora en la Universitat Pompeu Fabra de Barcelona. En esta universidad, además de dar clase, forma parte de un proyecto de investigación con el objetivo de aplicar la inteligencia artificial (IA) en las necesidades de la sociedad. En su tiempo libre se dedica a lanzar iniciativas para promover los estudios TIC entre las jóvenes.
Ana tituló su conferencia Ciencia para el bienestar planetario para explicar cómo se puede llegar a utilizar los datos con el objetivo de lograr un bienestar planetario. Esta idea la ejemplarizó con diferentes proyectos relacionados con la salud y el medio ambiente.
Salud mental
El primer caso práctico tuvo que ver con la salud mental; al año se producen 800.000 muertes por suicidio a nivel mundial. Esto significa que cada 40 segundos, ocurre un suicidio. En España, en 2017, la muerte por suicidio superó el doble a la muerte por accidentes de tráfico.
Ana y su equipo, como ingenieros, se preguntaron si podían hacer algo al respecto. La respuesta es que sí; muchas veces, las redes sociales son una plataforma en donde la gente con problemas mentales comunica sus sentimientos y emociones, aunque sea de manera sutil. Ejemplo de ello son los siguientes dos posts, escritos por dos personas antes de cometer un suicidio.

Twitter es una red social en el que se suelen expresar las personas susceptibles de cometer un suicidio.
Ana y su equipo lanzaron el proyecto STOP Suicide prevenTion in sOcial Platforms con el objetivo de crear un sistema que en tiempo real monitorizara las redes sociales con el objetivo de detectar usuarios con alto riesgo de suicidio. Además del suicidio, se quiso identificar también otros trastornos mentales y la depresión.
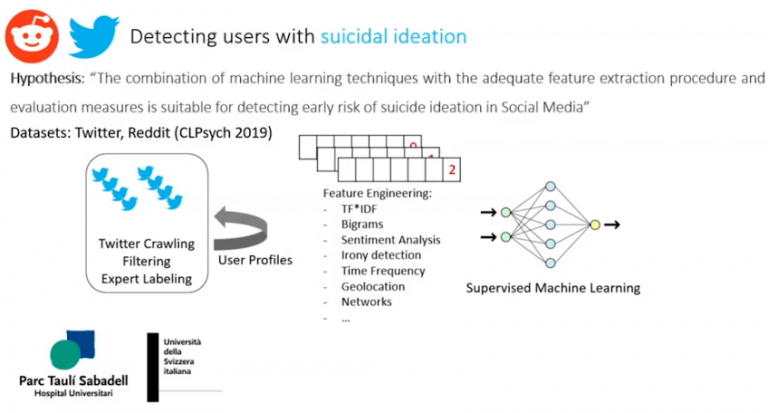
Una parte del proyecto pretende, tanto en Twitter como en Reddit, identificar a personas con tendencias suicidas. Para ello, se descargaron unas listas con palabras y frases identificadas por psicólogos como expresiones utilizadas por personas con estas conductas. Se realizó un filtrado para realizar un etiquetado manual para que los psicólogos identifiquen, uno a uno, el grado de tendencia suicida. Se tiene ene cuenta también la periodicidad en que se publican tuits, los favoritos o retuits que tienen las publicaciones para entender si tiene mucho apoyo o seguidores en las redes sociales. También la hora de las conexiones, ya que las personas con problemas mentales no tienen el sueño tan profundo y es posible que se conecten a horas no habituales.
Otro de estos proyectos se basa en la red social Reddit. El objetivo era, mediante el machine learning, identificar en esta red, gracias a los comentarios, a personas susceptibles a padecer trastornos mentales o depresión. El funcionamiento consiste en ir leyendo cada uno de los mensajes en orden temporal y secuencial para intentar predecir, lo antes posible, diferentes conductas. Interesa más identificar un usuario con posibles trastornos mentales que uno que ya los padece. El objetivo de prevenir. Se trata de trabajar con medidas de early risk.
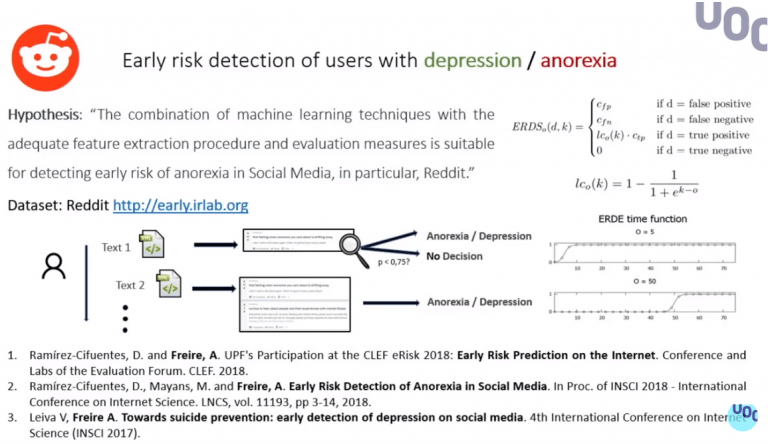
Otro proyecto en los que se encuentra Ana Freire es un sistema recomendador para personas que padecen Anorexia, utilizando datos en Twitter. Este sistema se basa en la idea de que las personas con Anorexia se proyectan en personas que ya han superado la enfermedad, teniéndolas como referente. El proyecto identifica a personas que tengan la enfermedad y personas que ya hayan pasado por ella mediante las palabras utilizadas, lo que dicen o cómo lo dicen. Obviamente, el proyecto integra a psicólogos que aconseja al equipo de Ana qué palabras utilizar para identificar estas conductas en los comentarios de los usuarios.
A los usuarios identificados con anorexia se les informa de otros usuarios que ya han superado la enfermedad. El objetivo es ayudarles mostrándoles un referente que haya pasado por lo mismo. Además, este contacto se realiza basándose en intereses en común para que la recomendación no sea tan intrusiva.
Enfermedades neurológicas
El objetivo de este nuevo estudio es predecir cuáles son los tests clínicos más determinantes para detectar la esclerosis múltiple. La motivación del proyecto es que 2,3 millones de personas en el mundo sufren esclerosis múltiple cuyo origen es aún desconocido.
Para el estudio, se utiliza un número determinado de usuarios y se extraen 73 características de todos ellos mediante diferentes tests. Con ello, que quiere identificar variables en común.
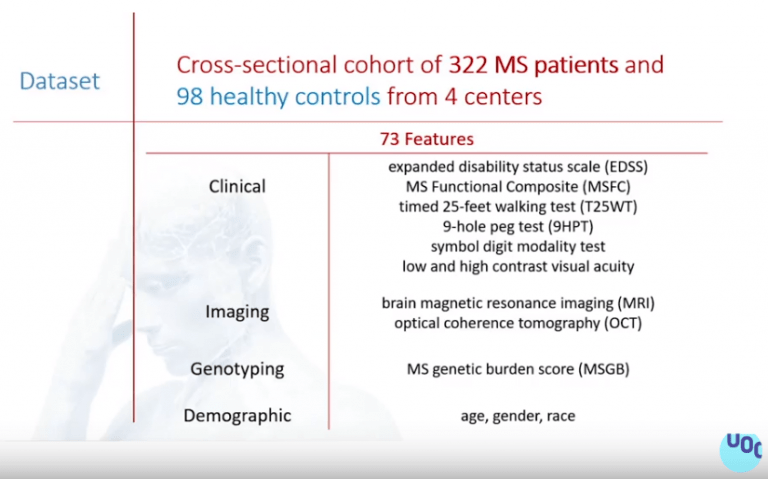
Es un proyecto que aún está en proceso, por lo que aún no hay resultados. Pero lo que sí que puede comentar Ana son los retos o challenges a los que están haciendo frente.
- Data set pequeño. Hay pocos ejemplos y esto puede llegar a ser un problema con la inteligencia artificial, por lo que la precisión del sistema es evidente.
- Datos erróneos. Al transcribirlos se puede colocar la coma donde no era, por ejemplo. Hablamos de errores humanos. Otros datos eran reales pero para el equipo de Ana eran outler.
- Datos perdidos. Había muchos pacientes que no tenían todos los tests clínicos realizados, por lo que había muchos datos en falta. En este caso, a veces se tira de estadísticas como la media o la moda, aunque no es aconsejable.
- No es un conjunto balanceado. Hay más pacientes con esclerosis múltiples que sanos, hubo que utilizar técnicas de compensación dando más peso a la clase minoritaria.
- Variables categóricas. Siempre que se trata con datos médicos que no sean numéricos, hay que transformarlos para que puedan ser entendidos por los programas de inteligencia artificial.

Los retos o challenges del proyecto
Sostenibilidad
Es un trabajo que tuvo que ver con la tesis doctoral de Ana. Los datos utilizados fueron difíciles de conseguir, ya que se obtenían mediante los motores de búsqueda. Para ello, Ana tuvo que contratar con Yahoo y Microsoft. Fue una línea de investigación complicada ya que los datos eran difíciles de obtener.
En 2015, Google reportó que había consumido en electricidad lo mismo que la ciudad de San Francisco. Las TIC suponen entre un 8% y un 10% de la energía consumida en Europa, con un 4% de las emisiones de carbono.
Los documentos en Google aumentan año tras año. Pero el buscador tarda lo mismo, prácticamente, en buscar la información; a lo largo del tiempo, ha aumentado muchísimo la cantidad de documentos alojados en Google pero apenas se ha modificado el tiempo en encontrarlos, cuando debería haber sido al revés: a mayor cantidad de documentos, mayor será el tiempo en encontrarlos.

La latencia es el tiempo total desde que el usuario teclea lo que quiere buscar hasta que obtiene los resultados. Es fundamental para que un usuario se vuelva adicto a un motor de búsqueda, según diversos estudios; un usuario, cuanto menos tarde en encontrar una información en un servidor, más fiel le será. Esta información la conoce Google y la tiene en cuenta en su funcionamiento; Google facilita a una búsqueda muchos servidores para que el tiempo de búsqueda sea lo menor posible. De ahí tanto gasto energético, para la eficiencia a la hora de buscar una información.
¿Cómo reducir el consumo de electricidad manteniendo el tiempo de latencia?
La gráfica de a continuación representa las búsquedas de las personas a lo largo del día. Para que las consultas sean respondidas rápidamente, Google tiene muchos servidores encendidos. Ana, mediante diferentes fórmulas matemáticas y la ciencia de datos, pretendió que los servidores se vayan encendiendo o apagando en función de la cantidad de las búsquedas. La idea es no tener máquinas o servidores encendidas a la espera de búsquedas y que puedan dedicarse a otros trabajos.

El modelo que buscaba Ana quería balancear el consumo y la latencia. Para ello, se utilizaron datos históricos y datos de predicción en tiempo real.
El proyecto consiguió, en el mejor de los casos, reducir el consumo de energía en un 68% dañando la latencia únicamente en 8 milisegundos.
El último de los proyectos tiene que ver con las búsquedas en Yahoo; cuando las búsquedas demoran más de lo habitual, los usuarios tienden a abrir otra ventana para buscar otra información o, directamente, no hacen clics en las búsquedas obtenidas. De esta manera, el proyecto quería predecir este comportamiento en el usuario; prediciendo que va a abandonar una búsqueda, las búsquedas obtenidas podían ser parciales o basadas en cachés para priorizar el ahorro de energía.
El dataset era muy elevado, basado en treinta millones de consultas. Se extrajeron las características que se observan en la imagen a continuación, relacionadas con el usuario, la hora y el día, etc.

Con este método de clasificación, se aplicó una simulación que a cada unos milésimos de segundos, se podía predecir si el usuario iba a continuar la búsqueda o la iba a abandonar. Si el resultado era que iba a clicar, el procedimiento se repetía, es decir, constantemente se iba prediciendo si el usuario iba a continuar la búsqueda o no.
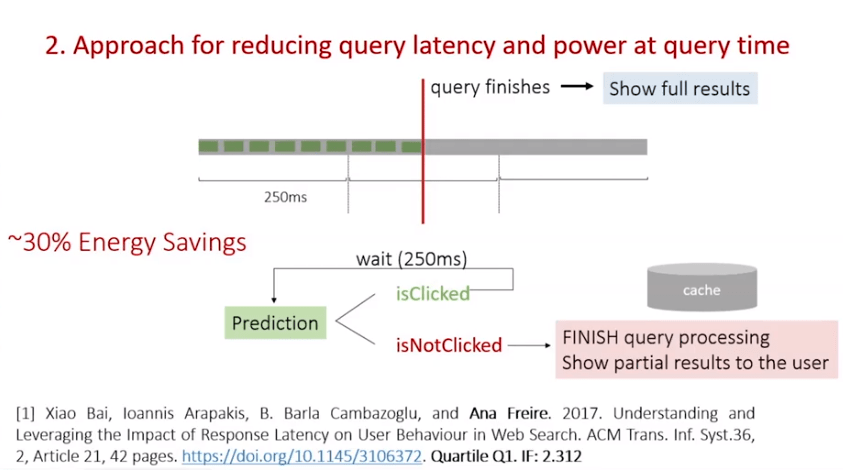
elevada .
El ahorro obtendio fue de un 30%.
Después de explicar estos proyectos de ciencia de datos, se abrió un turno de preguntas entre el público.



